WildWorld
A Large-Scale Dataset for Dynamic World Modeling
with Actions and Explicit State toward Generative ARPG
Introduction
Learning a predictive world model requires inferring latent states and modeling their action-conditioned transitions. However, existing datasets typically lack diverse action spaces, and actions are directly tied to visual observations rather than mediated by underlying states.
In many scenarios, actions manifest through implicit state transitions rather than explicit visual changes. For example, the action "shoot" affects internal state variables like "remaining ammunition", which cannot be reliably inferred from pixels alone, yet crucially determines future visual outcomes.
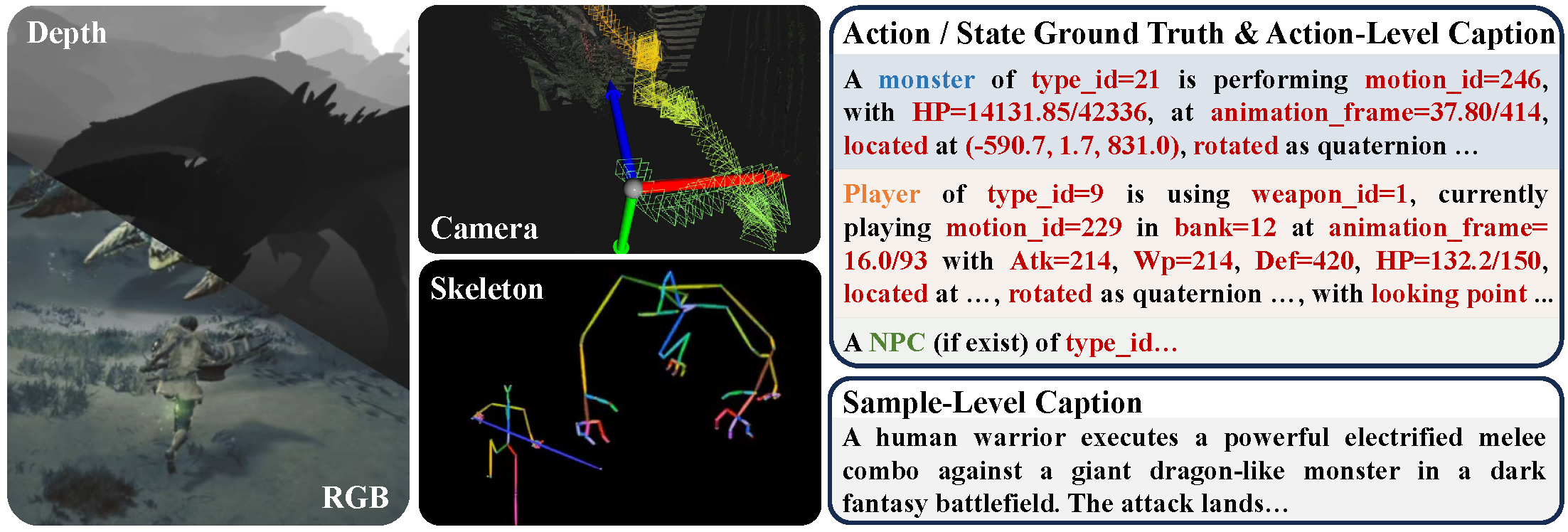
WildWorld addresses this by providing a large-scale action-conditioned world modeling dataset with explicit state annotations, automatically collected from Monster Hunter: Wilds — a photorealistic AAA action RPG. It contains RGB frames with aligned depth maps, camera poses, skeleton, and action / state ground truth. We provide both fine-grained action-level captions and sample-level captions, making the dataset applicable to various experimental settings.
Dataset Construction
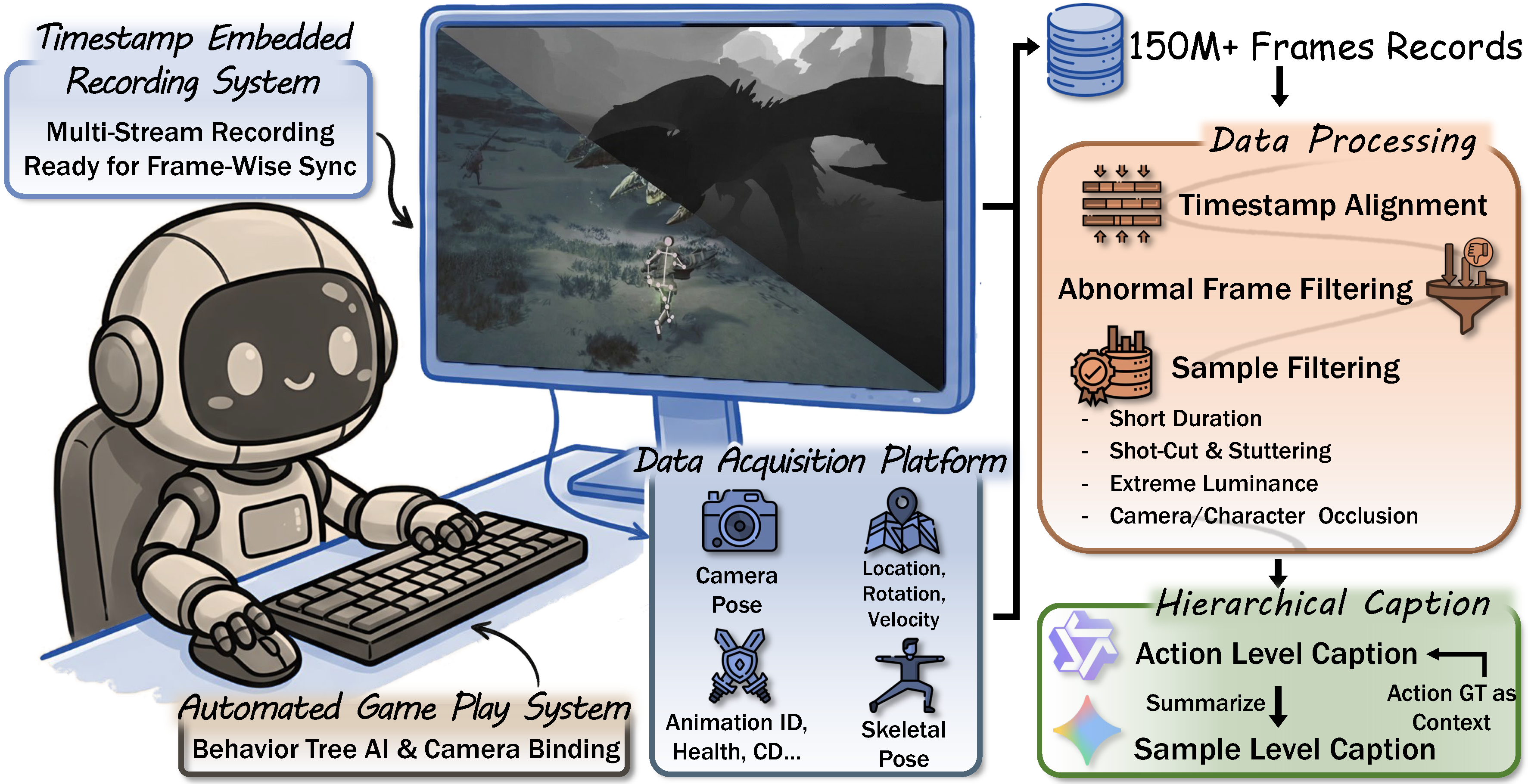
We design a fully automated pipeline with four stages: (1) Automated Game Play via programmatic UI navigation and behavior-tree-driven AI; (2) Multi-Stream Recording with timestamp-embedded frame-wise synchronization; (3) Data Processing & Filtering that removes short clips, shot-cuts, stuttering, extreme luminance, and occlusions; (4) Hierarchical Captioning with action-level captions grounded in state ground truth and sample-level summaries via LLM.
Dataset Overview
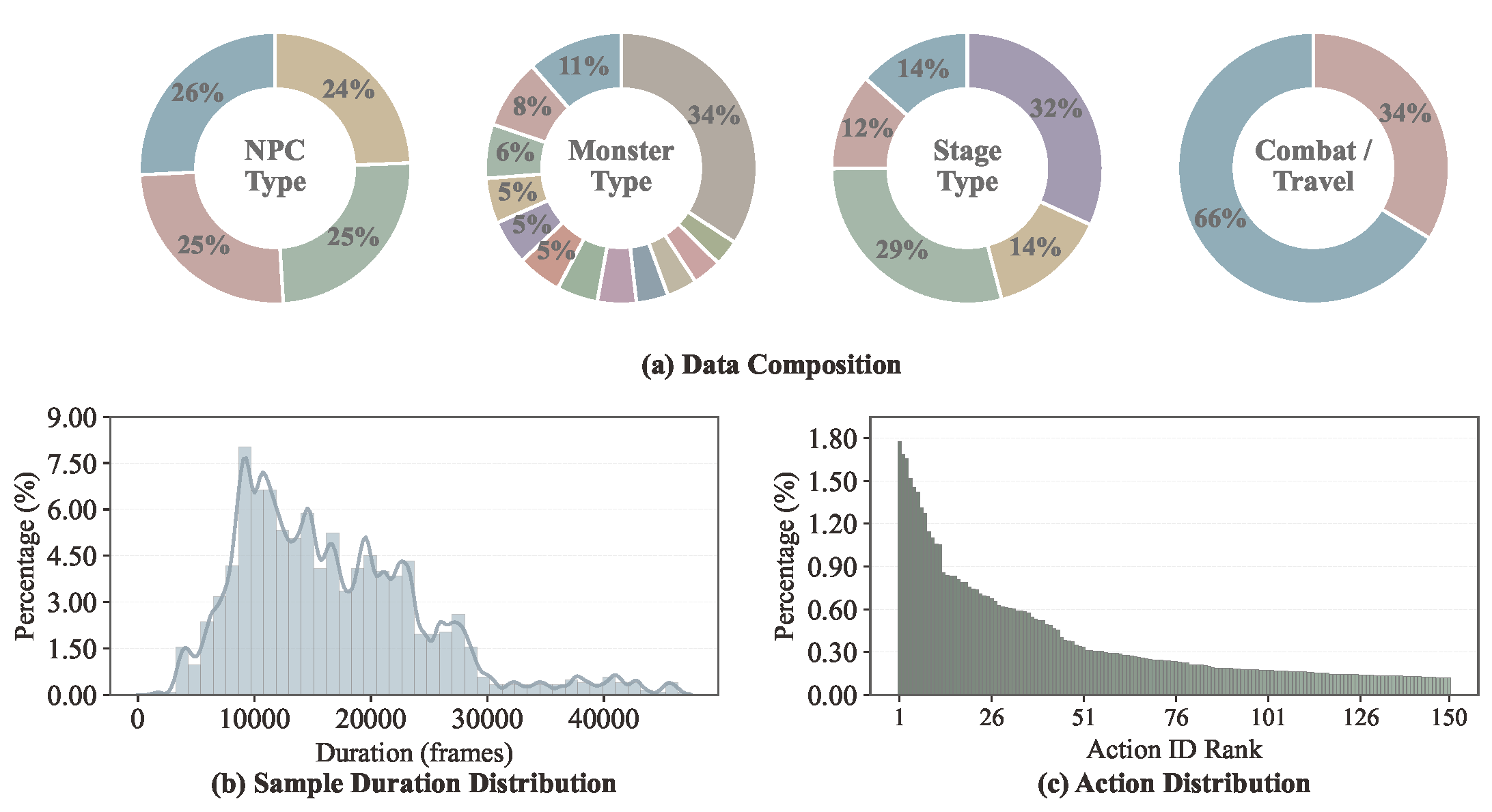
WildWorld contains 108M+ annotated frames with 450+ action types across 29 monster species, 4 player characters, 4 weapon types, and 5 distinct open-world stages. The dataset covers 66% combat and 34% traversal scenarios with a natural long-tail action distribution.
WildBench
We propose WildBench, a comprehensive benchmark with 200 curated test samples evaluating interactive world models from four perspectives:
- Video Quality — Motion Smoothness, Dynamic Degree, Aesthetic Quality, Image Quality (VBench).
- Camera Control — Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) via SfM.
- Action Following — Whether generated videos faithfully reflect input actions.
- State Alignment — Alignment between generated and ground truth state evolution via keypoint tracking.
Experiments
We evaluate several interactive video generation approaches on WildWorld under different conditioning settings:
- Baseline — Wan2.2-TI2V-5B, text+image-to-video generation without explicit control signals.
- CamCtrl — Camera-conditioned generation using ground-truth per-frame camera poses.
- SkelCtrl — Skeleton-conditioned generation taking rendered skeleton pose videos.
- StateCtrl — State-conditioned generation using camera, skeletons, and world states jointly.
- StateCtrl-AR — Autoregressive variant predicting states from the first frame only.
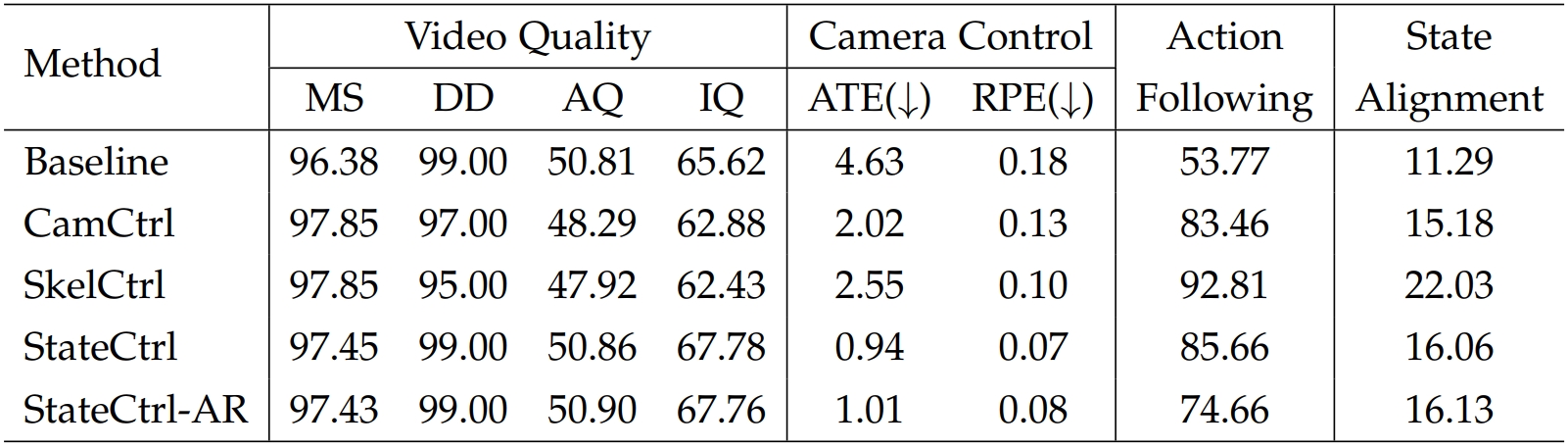
Quantitative comparison of different approaches trained on WildWorld and evaluated on WildBench.

Qualitative comparison of different approaches trained on WildWorld and evaluated on WildBench.
BibTeX
@misc{li2026wildworldlargescaledatasetdynamic,
title={WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG},
author={Zhen Li and Zian Meng and Shuwei Shi and Wenshuo Peng and Yuwei Wu and Bo Zheng and Chuanhao Li and Kaipeng Zhang},
year={2026},
eprint={2603.23497},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.23497},
}